
Updated on June 20, 2022
Usually when a huge site makes the decision to migrate to Drupal, one of the biggest concerns of the site owners is migrating the old site's data into the new Drupal site. The old site might or might not be a Drupal site, but given that the new site is on Drupal, we can make use of the cool migrate module to import data from a variety of data sources including but not limited to XML, JSON, CSV and SQL databases.
This article revolves around an example module named c11n_migrate showing how to go about importing basic data from a CSV data source, though things would work pretty similarly for other types of data sources.
👩💻 Get up to speed on Drupal 9! Watch Evolving Web and Pantheon's webinar on Drupal migrations.
The Drupal Migration Tutorial Series
- Part 1: Migrating Basic Data (you are here!)
- Part 2: Migrating Taxonomy Terms and Term References
- Part 3: Migrating Files and Images
- New: Migrating Hierarchical Taxonomy Terms
- Coming soon: Migrating Media Items and Their Relationships
The Problem
As per project requirements, we wish to import certain data for an educational and cultural institution.
- Academic programs: We have a CSV file containing details related to academic programs. We are required to create nodes of type program with the data. This is what we discuss in this article.
- Tags: We have a CSV file containing details related to tags for these academic programs. We are required to import these as terms of the vocabulary named tags. This will be discussed in a future article.
- Images: We have images for each academic program. The base name of the images are mentioned in the CSV file for academic programs. To make things easy, we have only one image per program. This will be discussed in a future article.
Executing Migrations
Before we start with actual migrations, a few things to note about running your migrations:
- Though the basic migration framework is a part of the D8 core as the migrate module, to be able to execute migrations, you must install the migrate_tools module. You can use the command
drush migrate-import --allto execute all migrations. In this tutorial, we also install some other modules like migrate_plus, migrate_source_csv. - Migration definitions in Drupal are in YAML files, which is great. But the fact that they are located in the
config/installdirectory implies that these YAML files are imported when the module is installed. Hence, any subsequent changes to the YAML files would not be detected until the module is re-installed. We solve this problem by re-importing the relevant configurations manually likedrush config-import --partial --source=path/to/module/config/install. - While writing a migration, we usually update the migration over and over and re-run them to see how things go. To do this quickly, you can re-import config for the module containing your custom migrations (in this case the c11n_migrate module) and execute the relevant migrations in a single command like
drush config-import --partial --source=sites/sandbox.com/modules/c11n_migrate/config/install -y && drush migrate-import --group=c11n --update -y. - To execute the migrations in this example, you can download the c11n_migrate module sources and rename the downloaded directory to c11n_migrate. The module should work without any trouble for a standard Drupal install.
The Module
Though a matter of personal preference, I usually prefer to name project-specific custom modules with a prefix of c11n_ (being the numeronym for the word customization). That way, I have a naming convention for custom modules and I can copy any custom module to another site without worrying about having to change prefixes. Very small customizations, can be put into a general module named c11n_base.
To continue, there is nothing fancy about the module definition as such. The c11n_migrate.info.yml file includes basic project definition with certain dependencies on other modules. Though the migrate module is in Drupal core, we need most of these dependencies to enable / enhance migrations on the site:
- migrate: Without the migrate module, we cannot migrate!
- migrate_plus: Improves the core migrate module by adding certain functionality like migration groups and usage of YML files to define migrations. Apart from that, this module includes an example module which I referred to on various occasions while writing my example module.
- migrate_tools: General-purpose drush commands and basic UI for managing migrations.
- migrate_source_csv: The core migrate module provides a basic framework for migrations, which does not include support for specific data sources. This module makes the migrate module work with CSV data sources.
Apart from that, we have a c11n_migrate.install file to re-position the migration source files in the site's public:// directory. Most of the migration magic takes place in config/install/migrate_plus.* files.
Migration Group
Like we used to implement hook_migrate_api() in Drupal 7 to declare the API version, migration groups, individual migrations and more, after Drupal 8, we do something similar. Instead of implementing a hook, we create a migration group declaration inside the config/install directory of our module. The file must be named something like migrate_plus.migration_group.NAME.yml where NAME is the machine name for the migration group, in this case, migrate_plus.migration_group.c11n.yml.
id: c11n
label: Custom migrations
description: Custom data migrations.
source_type: CSV files
dependencies:
enforced:
module:
- c11n_migrateWe create this group to act as a container for all related migrations. As we see in the extract above, the migration group definition defines the following:
- id: A unique ID for the migration. This is usually the NAME part of the migration group declaration file name as discussed above.
- label: A human-friendly name of the migration group as it would appear in the UI.
- description: A brief description about the migration group.
- source_type: This would appear in the UI to provide a general hint as to where the data for this migration comes from.
- dependencies: This segment is used to define modules on which the migration depends. When one of these required modules are missing/removed, the migration group is also automatically removed.
Once done, if you install/re-install the c11n_migrate module and visit the admin/structure/migrate page, you should see the migration group we created above!

Migration Definition: Metadata
Now that we have a module to put our migration scripts in and a migration group for grouping them together, it's time we write a basic migration! To get started, we import basic data about academic programs, ignoring complex stuff such as tags, files, etc. In Drupal 7 we used to do this in a file containing a PHP class which used to extend the Migration class provided by the migrate module. After Drupal 8, like many other things, we do this in a YML file, in this case, the migrate_plus.migration.program_data.yml file.
id: program_data
label: Academic programs and associated data.
migration_group: c11n
migration_tags:
- academic program
- node
# migration_dependencies:
# optional:
# - program_tags
# - program_image
dependencies:
enforced:
module:
- c11n_migrateIn the above extract, we declare the following metadata about the migration:
- id: A unique identifier for the migration. In this example, I allocated the ID program_data, hence, the migration declaration file has been named
migrate_plus.migration.program_data.yml. We can specifically execute this with the commanddrush migrate-import ID. - label: A human-friendly name of the migration as it would appear in the UI.
- migration_group: This puts the migration into the migration group c11n we created above. We can execute all migrations in a given group with the command
drush migrate-import --group=GROUP. - migration_tags: Here we provide multiple tags for the migration and just like groups, we can execute all migrations with the same tag using the command
drush migrate-import --tag=TAG - dependencies: Just like in case of migration groups, this segment is used to define modules on which the migration depends. When one of these required modules are missing / removed, the migration is automatically removed.
- migration_dependencies: This element is used to mention IDs of other migrations which must be run before this migration. For example, if we are importing articles and their authors, we need to import author data first so that we can refer to the author's ID while importing the articles. Note that we can leave this undefined / commented for now as we do not have any other migrations defined. I defined this section only after I finished writing the migrations for tags, files, etc.
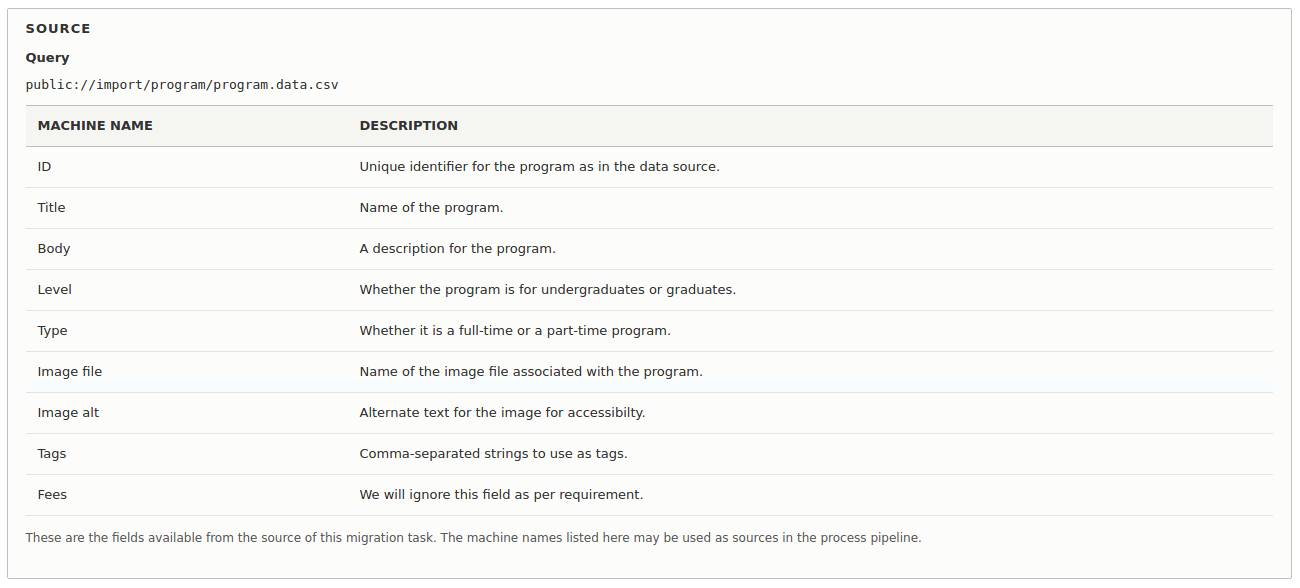
Migration Definition: Source
source:
plugin: csv
path: 'public://import/program/program.data.csv'
header_row_count: 1
keys:
- ID
fields:
ID: Unique identifier for the program as in the data source.
Title: Name of the program.
Body: A description for the program.
Level: Whether the program is for undergraduates or graduates.
Type: Whether it is a full-time or a part-time program.
Image file: Name of the image file associated with the program.
Image alt: Alternate text for the image for accessibility.
Tags: Comma-separated strings to use as tags.
Fees: We will ignore this field as per requirement.Once done with the meta-data, we define the source of the migration data with the source element in the YAML.
- plugin: The plugin responsible for reading the source data. In our case we use the migrate_source_csv module which provides the source plugin csv. There are other modules available for other data sources like JSON, XML, etc.
- path: Path to the data source file - in this case, the program.data.csv file.
- header_row_count: This is a plugin-specific parameter which allows us to skip a number of rows from the top of the CSV. I found this parameter reading the plugin class file
modules/contrib/migrate_source_csv/src/Plugin/migrate/source/CSV.php, but it is also mentioned in the docs for the migrate_source_csv module. - keys: This parameter defines a number of columns in the source data which form a unique key in the source data. Luckily in our case, the
program.data.csvprovides a unique ID column so things get easy for us in this migration. This unique key will be used by the migrate module to relate records from the source with the records created in our Drupal site. With this relation, the migrate module can interpret changes in the source data and update the relevant data on the site. To execute an update, we use the parameter--updatewith ourdrush migrate-importcommand, for exampledrush migrate-import --all --update. - fields: This parameter provides a description for the various columns available in the CSV data source. These descriptions just appear in the UI and explain purpose behind each column of the CSV.
- constants: We define certain values which we would be hard-coding into certain properties which do not have relevant columns in the data-source.
Once done, the effect of the source parameter should be visible on the admin/structure/migrate/manage/c11n/migrations/program_data/source page as follows:
Migration Definition: Destination
destination:
plugin: 'entity:node'
default_bundle: programIn comparison to the source definition, the destination definition is much simpler. Here, we need to tell the migrate module how we want it to use the source data. We do this by specifying the following parameters:
- plugin: Just like source data is handled by separate plugins, we have destination plugins to handle the output of the migrations. In this case, we want Drupal to create node entities with the academic program data, so we use the entity:node plugin.
- default_bundle: Here, we define the type of nodes we wish to obtain using the migration. Though we can override the bundle for individual item, this parameter provides a default bundle for entities created by this migration. We will be creating only program nodes, so we mention that here.
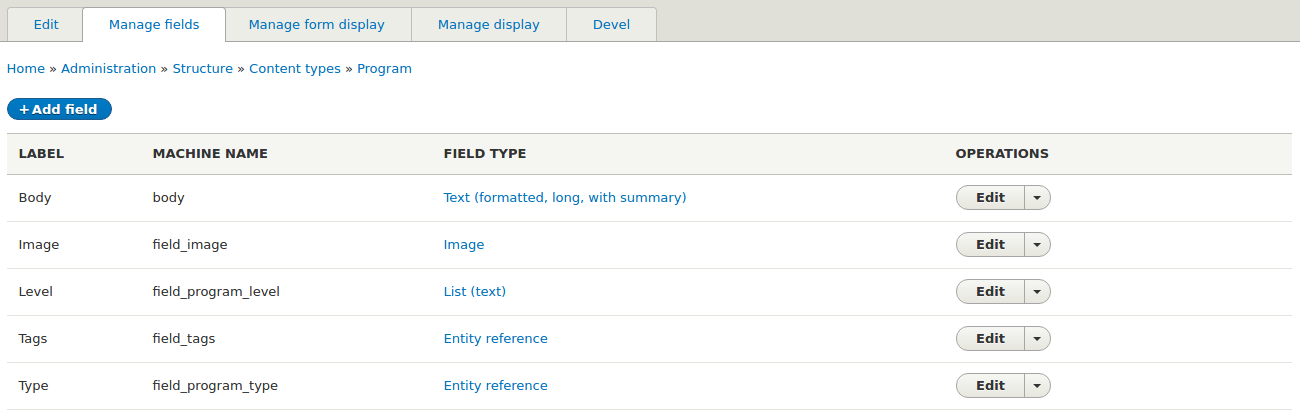
Provided above is a quick look at the program node fields.
Migration Definition: Mapping and Processing
If you ever wrote a migration in an earlier version of Drupal, you might already know that migrations are usually not as simple as copying data from one column of a CSV file to a given property of the relevant entity. We need to process certain columns and eliminate certain columns and much more. In Drupal, we define these processes using a process element in the migration declaration. This is where we put our YAML skills to real use.
process:
title: Title
sticky: constants/bool_0
promote: constants/bool_1
uid: constants/uid_root
'body/value': Body
'body/format': constants/restricted_html
field_program_level:
-
plugin: callback
callable: strtolower
source: Level
-
plugin: default_value
default_value: graduate
-
plugin: static_map
map:
graduate: gr
undergraduate: ugHere is a quick look at the parameters we just defined:
- title: An easy property to start with, we just assign the Title column of the CSV as the title property of the node. Though we do not explicitly mention any plugin for this, in the background, Drupal uses the get plugin to handle this property.
- sticky: Though Drupal can apply the default value for this property if we skip it (like we have skipped the status property), I wanted to demonstrate how to specify a hard-coded value for a property. We use the constant constants/bool_0 to make the imported nodes non-sticky with sticky = 0.
- promote: Similarly, we ensure that the imported nodes are promoted to the front page by assigning constants/bool_1 for the promote property.
- uid: Similarly, we specify default owner for the article as the administrative user with uid = 1.
- body: The body for a node is a filtered long text field and has various sub-properties we can set. So, we copy the Body column from the CSV file to the
body/valueproperty (instead of assigning it to just body). In the next line, we specify thebody/formatproperty asrestricted_html. Similarly, one can also add a custom summary for the nodes using thebody/summaryproperty. However, we should keep in mind that while defining these sub-properties, we need to wrap the property name in quotes because we have a/in the property name. - field_program_level: With this property I intend to demonstrate a number of things - multiple plugins, the static_map plugin, the callback plugin and the default_value plugin.
- Here, we have the plugin specifications as usual, but we have small dashes with which we are actually defining an array of plugins or a plugin pipeline. The plugins would be called one by one to transform the source value to a destination value. We specify a source parameter only for the first plugin. For the following plugins, the output of the previous plugin would be used as the input.
- The source data uses the values graduate/undergraduate with variations in case as Undergraduate or UnderGraduate. With the first plugin, we call the function strtolower (with
callback: strtolower) on the Level property (withsource: Level) to standardize the source values. After this plugin is done, all Level values would be in lower-case. - Now that the values are in lower-case, we face another problem. The Math & Economics row, no Level value is specified. If no value exists for this property, the row would be ignored during migration. As per client's instructions, we can use the default value graduate when a Level is not specified. So, we use the default_value plugin (with
plugin: default_value) and assign the value graduate (usingdefault_value: graduate) for rows which do not have a Level. Once this plugin is done, all rows would technically have a value for Level. - We notice that the source has the values graduate/undergraduate, whereas the destination field only accepts gr/ug. In Drupal 7, we would have written a few lines of code in a
ProgramDataMigration::prepareRow()method, but after Drupal 8, we just write some more YAML. To tackle this, we pass the value through a static_map (withplugin: static_map) and define a map of new values which should be used instead of old values (with themapelement). And we are done! Values would automatically be translated to gr or ug and assigned to our program nodes.
With the parameters above, we can write basic migrations with basic data-manipulation. If you wish to see another basic migration, you can take a look at migrate_plus.migration.program_tags.yml. Here is how the migration summary looks once the migration has been executed.
$ drush migrate-import program_data --update
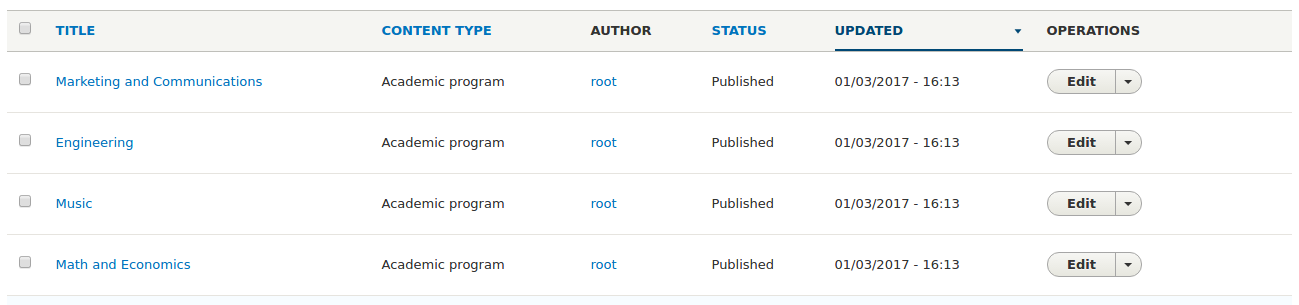
Processed 4 items (4 created, 0 updated, 0 failed, 0 ignored) - done with 'program_data'Once done correctly, the nodes created during the migration should also appear in the content administration page just as expected.
Next Steps
- Check out the source files for the c11n_migrate module.
- Read about various migration process plugins and how they work.
- Check out the migration_plus module for some more migration examples.
- Read Part 2: Migrating Taxonomy Terms and Term References
- Read Part 3: Migrating Files and Images
